
概要
https://github.com/HKUDS/LightRAG
LightRAGは、香港大学のデータインテリジェンスラボと北京郵電大学による共同研究で開発されたRAGシステムです。内容を見るところ、GraphRAGの発展版という認識です。今回はGraphRAGとの違いをまとめて、その優位性を確認していきます。
LightRAGとGraphRAGの主な違い
| 特徴 | GraphRAG | LightRAG |
| 検索 | グラフ構造を使って情報を検索するが、単一のレベルで検索 | デュアルレベル検索:低レベルと高レベルの検索を組み合わせ、詳細情報と広範な情報を両方取得 |
| データの更新 | 新しいデータの統合に時間がかかる | 増分更新:新しいデータを追加してもグラフ全体を再処理せず、効率的に更新 |
| 検索オーバーヘッド | 大量のデータで検索が遅くなることがある | 重複排除やグラフの最適化により、検索オーバーヘッドが削減され、効率的な検索が可能 |
| 応答速度 | 複雑なクエリに対して応答速度が遅くなる可能性あり | 高速応答:グラフ構造から派生したキー値ペアで、クエリに迅速に応答 |
詳細
LightRAGは、以下の技術を採用して検索プロセスを強化しています。これは、応答の精度・速度ともに良くなる可能性が十分にあり、期待しています。
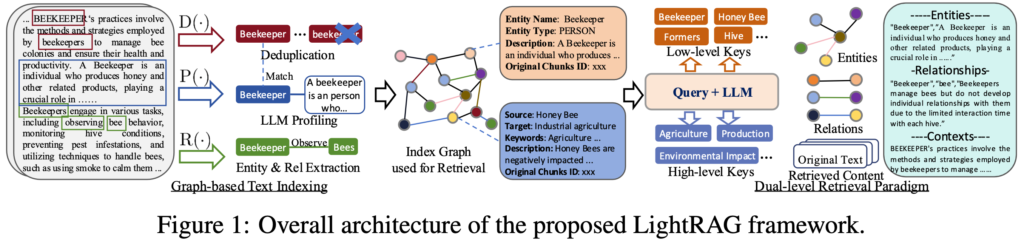
- エンティティと関係の抽出:LLMを使用して、ドキュメントからエンティティ(名前、場所、イベントなど)とそれらの関係を抽出します。これにより、文書全体をスキャンすることなく、重要な情報を効率的に取り出すことが可能です。たとえば、「東京」とか「オリンピック」がエンティティに当たります。そして、そのエンティティ同士がどうつながっているか、つまり「関係」を見つけます。「東京でオリンピックが開催された」というように、エンティティの関係を見つけることで、情報の流れが理解できます。
- グラフ構造の使用:ここはGraphRAGの部分ですが、ドキュメントから抽出されたエンティティや関係は、ナレッジグラフとして整理され、複数のドキュメント間のつながりを明確にします。これにより、クエリに対してより正確で包括的な情報を提供します。つまり、複数のデータが絡んだ質問にも的確に答えることができるようになるという事です。
- 重複排除:同一のエンティティや関係を結合することで、データの重複を防ぎ、グラフサイズを縮小します。これにより、効率的なデータ処理が可能になります。大量のデータがあると、同じ情報が何度も出てきてしまうことがあります。LightRAGは、同じエンティティや関係が重複しないように整理して、効率的にデータを管理しているという事みたいです。
- デュアル検索:LightRAGは、詳細指向のクエリ(特定のエンティティに焦点を当てた検索)と抽象的なクエリ(広範なテーマをカバーする検索)の両方に対応しています。このアプローチにより、複雑なクエリにも迅速かつ正確に応答します。
- 低レベル検索:特定のエンティティに関する詳細な情報を探します。例えば、「東京オリンピックで金メダルを取った選手は誰か?」というような質問には、詳細なデータを使って答えます。
- 高レベル検索:より広いテーマに対する答えを探します。たとえば、「オリンピックが経済に与える影響は?」というような質問には、関連するエンティティを幅広く検索し、全体的な見解を提供します。
https://github.com/HKUDS/LightRAG?tab=readme-ov-file
結論
いいところ
- 検索コストの削減:重複排除や検索オーバーヘッドの削減により、処理効率が高い。
- 効率的なグローバル情報の取得:複数のドキュメントにまたがる情報を高速かつ正確に取得。
- 柔軟で多様なクエリ対応:デュアルレベル検索により、幅広いクエリに対応。
- 迅速なデータ更新:段階的な更新により、新しいデータにも柔軟に対応。
ここからさらに検証を重ねていきたいですが、デュアルレベル検索や段階的にデータ更新できる点で、LightRAGは有用であると思います。また追加情報まとめれたら、記事にしていきます。

コメントを残す