

はじめに
本日は多くの企業でも注目の集まっているRAG(Retrieval-Augmented Generation)という手法について改めて解説します。
RAGとは簡単に説明するとLLMにおいて質問への返答や文章生成の際に、検索と生成を組みあせたアプローチのことです。これにより、外部データを参照してその情報をもとに文章を生成できるため、モデルの学習に使用されていない社内データなどを考慮した上で回答や文章を得ることができる素晴らしい手法です。
このRAGのなかで外部データを検索するために使用されるベクトルデータベースとは何か?また具体的な使用方法の例を紹介いたします。
ベクトルデータベースとは
ベクトルデータベースとは、テキストや画像、音声といったデータをベクトル化し、保存するデータベースです。このベクトルを検索のインデックスとして使用することで高度な検索を可能にします。
分かりやすいように簡単な図で説明します。
まずはこれまでのRDB(SQLなど)はこんな感じです。
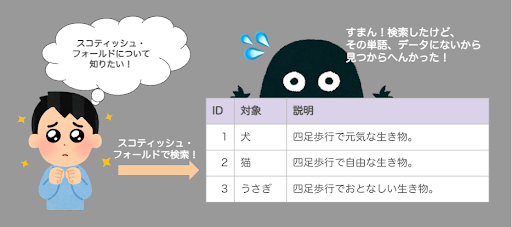
例えばユーザーが「スコティッシュ・フォールド(可愛い猫の種類)」の説明を知りたくて、その内容でDBに検索をかけたとします。
しかし、検索した単語と一致するデータがなければデータを取得することはできません。

次にベクトルデータベースの場合です。今回は「対象」カラムをベクトル化した想定で、
検索の際も「スコティッシュ・フォールド」という言葉をベクトル化したものを利用します。そうすることで、同じ言葉はなくとも最も類似性の高いレコードを取得することが可能になります。これは数学のお勉強でも習った、2つのベクトルの内積が1に近ければ、そのベクトルの類似性は高いという性質を利用した検索手法です。
まあ、こういうベクトル情報をインデックスに利用して検索できるのがベクトルデータベースですね!
ちなみにこういう情報をベクトル情報に変換することを”embedding”と言います。
RAGのアーキテクチャ
次に、ここまでの情報を踏まえて、RAGの簡単なアーキテクチャの図を見てもらうことで、なんとなくイメージを掴んでもらえるかと思います。
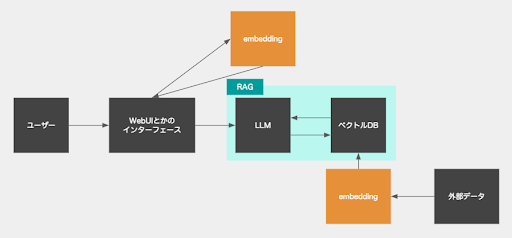
簡単にこんな感じです〜。なので回答生成時には検索時間は少し掛かります。
RAGを使用した文章生成時の実際の処理の手順
それでは次に実際の簡単な処理の手順を紹介します。
1. まずは、ベクトルデータベースを作ります。Indexにしたい文字列をembeddingでベクトル化しましょう。私はOpenAIのtext-embedding-3-small か text-embedding-3-largeを使います。(https://platform.openai.com/docs/guides/embeddings)
2. ユーザーからの入力文字列をembeddingでベクトル化します。
3. データベースの全てのIndexのベクトルと、ユーザーの入力のベクトルを総当たりでコサイン類似度を計算します。
4. コサイン類似度を昇順で並べて、一番上の値が最も類似度が高い値を採用します。
5. それをプロンプトに混ぜて、回答や文章を得ます。
最後に
最近はコンテキストに大量の文章を詰め込めるLLMも登場してきており、RAGが不要になるのではという話もありますが、私はそうは思いません。
コンテキストに大量の文章を詰め込むことで回答の精度が落ちるという研究結果があるため、RAGが不要になるのはもう少し先の話かなと思います。
今後は、もう少し深掘りした内容を記事にしようと思います。
例えば、「日本語のベクトル化に有効なembedding.appは何か?」や、「学習データと外部データで矛盾があった際に採用されるのはどちらか?」などを予定しています!

コメントを残す