

はじめに
GPT-SoVITSというゼロショットでTTSが可能なオープンソースを試してみました。
最近はBert-VITS2などの優秀なTTSがあるので、それと比べてどうなのかが気になりました。
GPT-SoVITSの特徴は下記4点がREADMEで記載されていました。
1.『ゼロショットTTS』:5秒の音声サンプルを入力して、即座にテキストから音声への変換が可能。
2.『フューショットTTS』:音声の類似性とリアリズムを向上させるために、たった1分のトレーニングデータでモデルを微調整可能。
3.『クロスリンガルサポート』:トレーニングデータセットと異なる言語での推論をサポートし、現在は英語、日本語、中国語に対応可能。
4.『WebUIツール』:音声伴奏の分離、自動トレーニングセットのセグメンテーション、中国語ASR、テキストラベリングなどの統合ツールを含み、初心者がトレーニングデータセットやGPT/SoVITSモデルを作成するのを支援している。
GPT-SoVITSのGitHub:https://github.com/RVC-Boss/GPT-SoVITS?tab=readme-ov-file
検証
簡単にデモが可能なhugging-faceがあったのでそこで軽く検証しました。
https://huggingface.co/spaces/litagin/gpt_sovits_demo
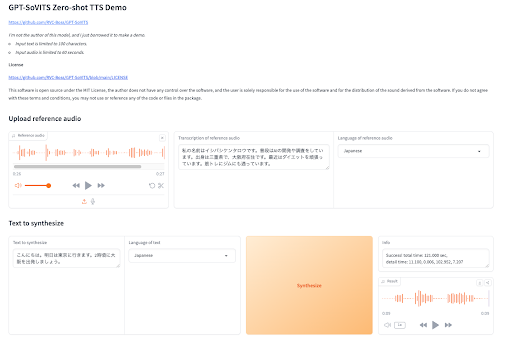
こんな画面です。
一応制約があって、入力の音声は1分以内で、文字起こしした場合は100文字以内である必要があります。
今回は27秒で80数文字の音声データを参照してTTSをしてみました。
とても簡単に試せるので良かったです!
検証結果
参照の音声がこんな感じ〜
TTS結果がこんな感じ〜
微妙ですが、27秒にしてはいいかもしれません。
またローカルに環境を作って、学習データで学習させた場合の結果も記事にしようと思います!

コメントを残す